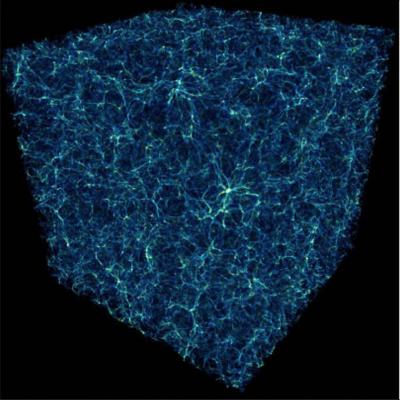
Credit: Jack Burns et al (Universiteit van Colorado)
De cijfers zijn hier al vaak verschenen op de astroblogs: 4% van het heelal bestaat uit gewone materie, 73% is donkere energie en 23% is donkere materie. Je zou dus kunnen denken ‘OK, die vier procent die uit gewone materie bestaat kan je wel zien’. Mis! Van die gewone materie kunnen sterrenkundigen slechts 60% zien in de vorm van sterren, planeten, gas- en stofwolken. De overige 40% is zoek. Met behulp van twee grote computers gingen Jack Burns en collega’s van de Universiteit van Colorado (Boulder, VS) daarom op zoek naar die verborgen materie. In een computersimulatie werd 2,5% van het zichtbare heelal gesimuleerd, een kubus van 1,5 miljard lichtjaar doorsnede. Uitkomst was dat veel materie blijkt te zitten in enorme intergalactische gaswolken, het zogenaamde Warme-Hete Intergalactische Medium (WHIM). De komende jaren wil men met echte telescopen deze stelling gaan bewijzen. De huidige generatie (ruimte-)telescopen is niet in staat om het WHIM te zien, maar een nieuwe generatie moet dat wel kunnen. Burns en z’n team denken daarbij aan de 10-meter South Pole Telescope op Antarctica en de 25-meter Cornell-Caltech Atacama Telescoop (CCAT), die momenteel in de Atacama woestijn in Chili wordt gebouwd. Morgen, 10 december dus, verschijnt een artikel in het vakblad The Astrophysical Journal over de zoektocht naar de verborgen materie. Dat artikel, getooid met de prachtige titel “The Santa Fe Light cone simulation project: I. Confusion and the WHIM in upcoming Sunyaev-Zel’dovich effect surveys” is voor ons astrobloglezers geen verborgen materie, want het is alhier te lezen. Nog eventjes over die computers waarop het spulletje gesimuleerd is. Burns et al hebben eerst zo’n tien jaar gewerkt aan de programmatuur ervan, de ruwe codes dus. Daarna werd het in twee super-PC’s gestopt, die van het San Diego Supercomputer Center en het National Center for Supercomputing Applications (Universiteit van Illinois) en die hebben beiden zo’n 500.000 processoruren nodig gehad om 60 terrabyte aan resultaten uit te spuwen. 😯 Dat plaatje hierboven is dus slechts een héél kleine visualisatie van die uitkomst. Die 60 Tb zal ik hier nog wel eens ter download aanbieden. 😉 Bron: Universiteit van Colorado.




Speak Your Mind